A tree data structure is a way to hold data that looks like a tree when it's visualized. For example:

All data points in a tree is called nodes. The top of the tree is called the root node and from the root it branches out into additional nodes called child node. Each of these child nodes may have more child nodes. Nodes with branches leading to other nodes are called the parent. And nodes that branches out from the parent is called child node and each children that parent of other tree makes their own subtree. Branches at the end of the tree which doesn't have any child is called leaf nodes.



What is Binary Search Tree?
A tree data structure can have any number of branches from every node but in binary tree each node only has two branches. And binary search tree is binary tree that is ordered. That means each left subtree is less than or equal to the parent node and each right subtree is greater than or equal to the parent node. In fact the picture above is a example to binary search tree.
Why Use Binary Search Tree?
Because the use the principle of binary search, on average the operations are able to skips about half of the tree. So, for each for search, insertion and deletion takes time proportional to the logarithm of number of items stored in the tree. For example, if we are looking for a small value, we only have to search through the left nodes and ignore the right children.
Binary search tree is also memory efficient because in array or in hash table we have take specific fixed amount of memory space and some of the indexes may remain empty. But in binary search tree we store the data by reference. As we add new data we take a chunk of memory and link to it.
When to Use Binary Search Tree?
Binary search tree is useful in case where elements can be compared to less than or greater than manner. For example- if we have bunch of names saved and we want to search a particular name.
Binary search tree will save the data in alphabetical order:
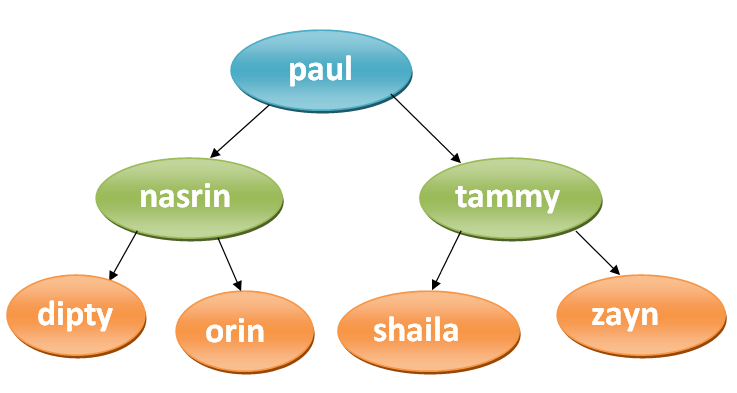
If we search for the name "orin' , we'll start at the root as the search key is less than the
root (orin < paul) then we'll go to the left child(nasrn). The left child less than the searched key
(orin > nasrin). So, we'll go to the right child which is the search key.

Time complexity
- Insertion: O(log n)
- Deletion: O(log n)
- Search: O(log n)







































